Most AI agents are one-shot: payload in, result out. That works when the answer is deterministic — classify this, extract that, format this response.
It breaks the moment the answer is uncertain and must be earned.
A fraud detection agent that correlates signals across multiple passes produces meaningfully better risk assessments than one that calls the LLM once and reports. A document extraction agent that checks its own output against a required-fields schema — and re-extracts when fields are missing — is more reliable than one that hopes the first parse was complete. A contract drafting agent whose first clause fails a compliance checklist needs to revise, not just stop.
These are two different problems. They share the same root cause — one-shot agents have nowhere to put uncertainty or quality feedback — but they need different structures to solve them.
K9-AIF ships both as first-class Architecture Building Blocks:
BaseValidationLoopAgent— for agents that must test a hypothesis, observe the result, and decide whether to try againBaseCriticActorAgent— for agents that must produce output, have it evaluated, and refine until it meets a quality bar
Pattern 1 — BaseValidationLoopAgent
The question it answers
“Is this hypothesis true — and am I confident enough to act on it?”
The loop runs until the agent is sure, gives up, or hits a cap.
Loop structure
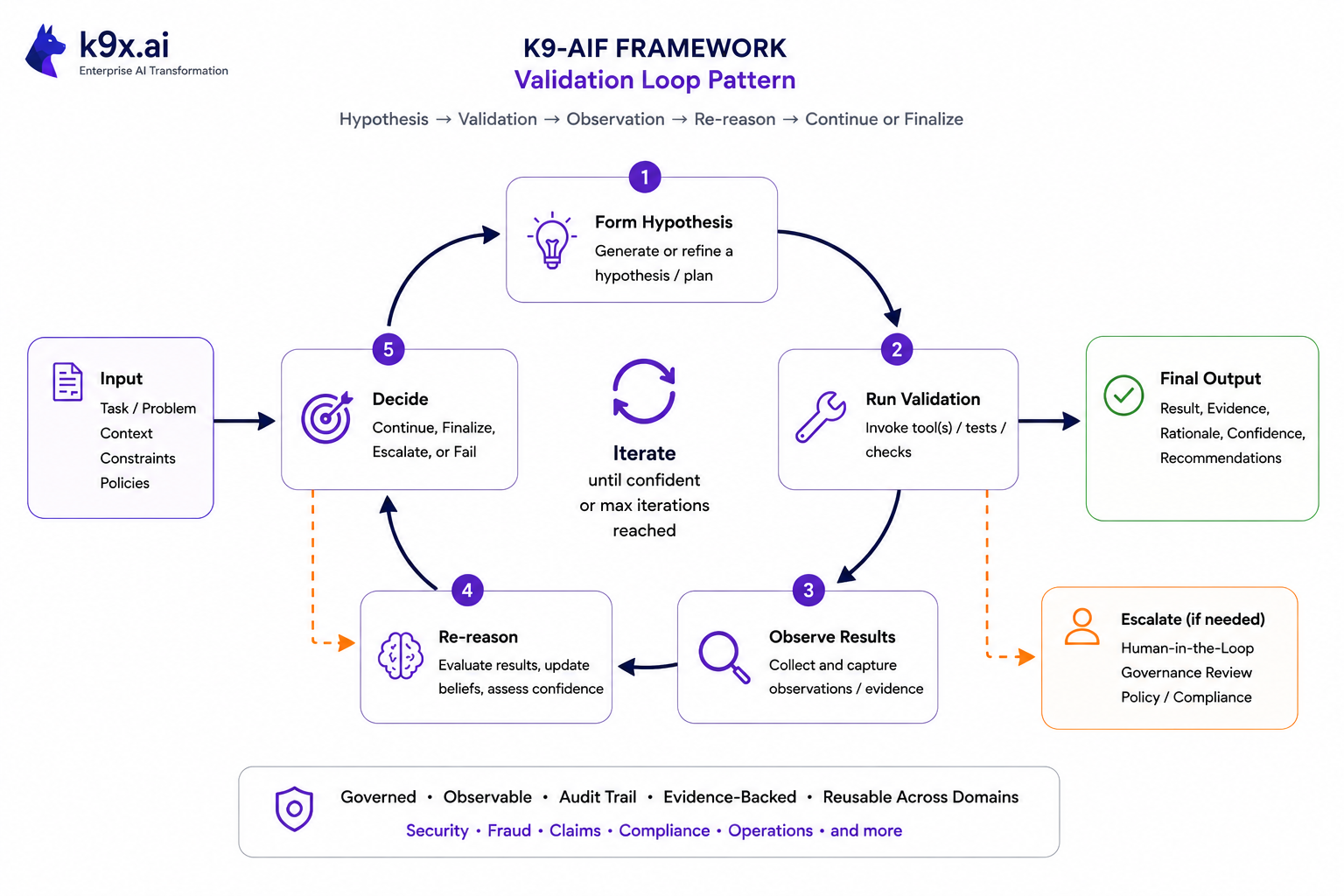
Every iteration runs the same four steps:
- Generate hypothesis — form the next thing to test, informed by prior iterations
- Run validation — invoke the tool, rule engine, database, or LLM that tests it
- Evaluate observation — interpret the raw result into a structured observation with a confidence score
- Decide — return a disposition
| Disposition | Meaning |
|---|---|
CONTINUE |
Confidence insufficient — run another iteration |
FINALIZE |
Confidence sufficient — produce validated output |
ESCALATE |
Unresolvable — route to human-in-the-loop |
FAIL |
Definitive negative result |
How it is built
The ABB lives in k9_aif_abb/k9_agents/validation/. Five abstract methods define the contract. The loop skeleton is fixed.
from k9_aif_abb.k9_agents.validation import (
BaseValidationLoopAgent,
ValidationDisposition,
ValidationLoopContext,
ValidationLoopResult,
)
class ClaimsEvidenceAgent(BaseValidationLoopAgent):
layer = "ClaimsEvidenceAgent SBB"
def generate_hypothesis(self, loop_ctx: ValidationLoopContext):
prior = loop_ctx.steps[-1].observation if loop_ctx.steps else {}
return {
"query": "policy_coverage",
"claim_id": loop_ctx.payload["claim_id"],
"focus": prior.get("gaps", []),
}
def run_validation(self, hypothesis, loop_ctx: ValidationLoopContext):
return policy_engine.check(hypothesis)
def evaluate_observation(self, tool_result, loop_ctx: ValidationLoopContext):
return {
"covered": tool_result.get("covered"),
"gaps": tool_result.get("gaps", []),
"confidence": tool_result.get("match_score", 0.0),
}
def should_continue(self, observation, loop_ctx: ValidationLoopContext):
threshold = self.config.get("confidence_threshold", 0.8)
if observation["confidence"] >= threshold:
return ValidationDisposition.FINALIZE
if loop_ctx.iteration >= 3 and observation["confidence"] < 0.4:
return ValidationDisposition.ESCALATE
return ValidationDisposition.CONTINUE
def finalize(self, loop_ctx: ValidationLoopContext) -> ValidationLoopResult:
last = loop_ctx.steps[-1]
return ValidationLoopResult(
disposition = ValidationDisposition.FINALIZE,
output = {"decision": "approved", "confidence": last.confidence},
steps = loop_ctx.steps,
iterations = loop_ctx.iteration,
final_confidence = last.confidence,
evidence = [str(s.observation) for s in loop_ctx.steps],
)
All domain logic is in those five methods. The loop, step history, telemetry, error handling, cap enforcement — all in the ABB.
OOB implementation — K9ValidationLoopAgent
Just as K9ModelRouter is the ready-to-run OOB implementation of BaseModelRouter, K9ValidationLoopAgent is the OOB implementation of BaseValidationLoopAgent. The LLM is the validation tool. Override only what differs:
from k9_aif_abb.k9_agents.validation import K9ValidationLoopAgent
class FraudDetectionAgent(K9ValidationLoopAgent):
layer = "FraudDetectionAgent SBB"
def run_validation(self, hypothesis, loop_ctx):
# Swap in a rule engine — everything else is inherited OOB
return fraud_rule_engine.evaluate(loop_ctx.payload)
When to use it
- Fraud signal correlation — iterate until risk confidence is sufficient
- Claims evidence — policy coverage checks until adjudication confidence is sufficient
- Security exploit validation — attempt, observe, confirm or rule out
- Compliance gap assessment — regulation lookup until gap coverage is sufficient
- Document extraction confidence — re-extract until required fields are present
Config
max_iterations: 5
confidence_threshold: 0.8
finalize_on_max_iterations: true
escalate_on_tool_error: false
Pattern 2 — BaseCriticActorAgent
The question it answers
“Is this output good enough — and if not, what specifically should be fixed?”
The Actor produces. The Critic evaluates and lists issues. The Actor revises. The loop continues until the Critic accepts or the round cap is hit.
Loop structure
Round 1: generate() → critique() → should_accept()
Round 2+: refine() → critique() → should_accept()
...
Terminal: ACCEPTED → finalize()
ESCALATE → escalate()
FAIL → fail()
| Disposition | Meaning |
|---|---|
ACCEPTED |
Critic is satisfied — produce final output |
REJECTED |
Issues found — Actor must refine and retry |
ESCALATE |
Cannot converge — route to human-in-the-loop |
FAIL |
Definitively unacceptable — cannot be fixed |
How it is built
The ABB lives in k9_aif_abb/k9_agents/critic_actor/. Five abstract methods define the contract.
from k9_aif_abb.k9_agents.critic_actor import (
BaseCriticActorAgent,
CriticActorContext,
CriticActorDisposition,
CriticActorResult,
)
class ContractDraftingAgent(BaseCriticActorAgent):
layer = "ContractDraftingAgent SBB"
def generate(self, ctx: CriticActorContext):
return llm.draft_clause(ctx.payload)
def critique(self, draft, ctx: CriticActorContext):
issues = compliance_checker.scan(draft)
score = 1.0 if not issues else max(0.0, 1.0 - len(issues) * 0.2)
return {
"accepted": not issues,
"score": score,
"issues": issues,
"summary": f"{len(issues)} compliance issues found",
}
def refine(self, draft, feedback, ctx: CriticActorContext):
return llm.revise_clause(draft, feedback["issues"])
def should_accept(self, feedback, ctx: CriticActorContext):
if feedback.get("accepted") or feedback.get("score", 0) >= 0.9:
return CriticActorDisposition.ACCEPTED
return CriticActorDisposition.REJECTED
def finalize(self, ctx: CriticActorContext) -> CriticActorResult:
last = ctx.steps[-1]
return CriticActorResult(
disposition = CriticActorDisposition.ACCEPTED,
output = {"clause": last.draft, "score": last.score},
steps = ctx.steps,
rounds = ctx.round,
final_score = last.score,
)
OOB implementation — K9CriticActorAgent
K9CriticActorAgent is the OOB implementation — the LLM plays both Actor and Critic roles using role-switched system prompts. Override critique() to plug in a real external validator:
from k9_aif_abb.k9_agents.critic_actor import K9CriticActorAgent
class SchemaExtractionAgent(K9CriticActorAgent):
layer = "SchemaExtractionAgent SBB"
def critique(self, draft, ctx):
# Swap in Pydantic schema validator — everything else is inherited OOB
try:
data = json.loads(draft)
missing = REQUIRED_FIELDS - set(data.keys())
score = 1.0 if not missing else max(0.0, 1.0 - len(missing) * 0.3)
return {
"accepted": not missing,
"score": score,
"issues": [f"missing: {f}" for f in sorted(missing)],
"summary": "schema valid" if not missing else f"{len(missing)} fields missing",
}
except Exception:
return {"accepted": False, "score": 0.0, "issues": ["not valid JSON"], "summary": "parse error"}
When to use it
- Contract drafting — Actor writes clause, Critic checks compliance checklist
- Schema extraction — Actor extracts JSON, Critic validates required fields
- Report improvement — Actor drafts, Critic scores quality and lists issues
- Policy language refinement — Actor writes, Critic checks regulatory alignment
- Code generation — Actor writes function, Critic runs unit tests and returns error traces
Config
max_rounds: 3
acceptance_threshold: 0.8
finalize_on_max_rounds: true
escalate_on_critic_error: false
When to use which
The tell is the question the agent is trying to answer:
| Question | Pattern |
|---|---|
| “Is this hypothesis true?” | BaseValidationLoopAgent |
| “Is this output good enough?” | BaseCriticActorAgent |
More concretely:
| Scenario | Pattern | Why |
|---|---|---|
| Fraud signal correlation | Validation Loop | Testing whether signals confirm fraud |
| Claims evidence | Validation Loop | Testing whether coverage holds |
| Security exploit confirmation | Validation Loop | Testing whether a vulnerability is real |
| Contract clause drafting | Critic-Actor | Improving output against a compliance bar |
| JSON schema extraction | Critic-Actor | Refining output until required fields are present |
| Report generation | Critic-Actor | Improving quality until the Critic accepts |
One-shot agents (BaseAgent) remain the right default for triage, routing, guard, audit, and graph sync — tasks that produce their answer in a single pass. The iterative patterns are an explicit SA design-time decision, not an automatic upgrade.
Both are invisible to the caller
From the Squad’s perspective, both patterns look identical to a plain BaseAgent:
flow:
- agent: ClaimsTriageAgent # one-shot
result_key: triage
- agent: FraudDetectionAgent # ValidationLoop — may iterate 1–5 times internally
result_key: fraud
- agent: ContractDraftingAgent # CriticActor — may refine 1–3 times internally
result_key: contract
- agent: AuditAgent # one-shot
result_key: audit
The Squad calls execute(payload) and receives a dict. The number of internal iterations is an implementation detail. The squad contract, the orchestrator contract, the agent YAML — none of these change.
State contracts in models/
Both ABBs follow the same separation principle: data contracts live in models/, separate from execution logic.
| Package | Models |
|---|---|
k9_agents/validation/models/ |
ValidationLoopContext, ValidationLoopStep, ValidationLoopResult, ValidationDisposition |
k9_agents/critic_actor/models/ |
CriticActorContext, CriticActorStep, CriticActorResult, CriticActorDisposition |
Loop state can be persisted to PostgreSQL, written to the Neo4j knowledge graph, fed into telemetry dashboards, or serialized for human review — without touching the agent implementation.
Inheritance hierarchy
BaseAgent
├── BaseValidationLoopAgent (hypothesis-test-observe ABB)
│ └── K9ValidationLoopAgent (LLM-driven OOB)
│ └── FraudDetectionAgent / ClaimsEvidenceAgent (domain SBB)
│
└── BaseCriticActorAgent (actor-critic-refine ABB)
└── K9CriticActorAgent (LLM-driven OOB)
└── ContractDraftingAgent / SchemaExtractionAgent (domain SBB)
Both OOB implementations follow the same principle as K9ModelRouter — ready to use without modification, extensible by overriding only what the domain requires.
Tests
K9ValidationLoopAgent— 16 tests covering convergence, caps, escalation, JSON parsing, subclass extension. Seek9_aif_abb/tests/test_k9_validation_loop_agent.py.K9CriticActorAgent— 15 tests covering acceptance, refinement, max-round behaviour, critic errors, JSON parsing, subclass extension (SchemaValidatorAgent). Seek9_aif_abb/tests/test_k9_critic_actor_agent.py.
All tests are fully offline — no LLM or network required.
EOC reference
The K9X Enterprise Insurance Operations Center implements both patterns:
FraudDetectionAgent—K9ValidationLoopAgent; iterates rule signals + LLM until risk confidence is sufficientDocumentExtractorAgent—K9ValidationLoopAgent; OCR runs once on iteration 1, cached; re-extracts until required fields are present
The full EOC architecture — squads, agents, orchestrators, and the K9ValidationLoopAgent ABB node — is navigable as a live knowledge graph at graph.k9x.ai, under the Examples tab.
BaseValidationLoopAgent, K9ValidationLoopAgent, BaseCriticActorAgent, and K9CriticActorAgent are available in k9_aif_abb/k9_agents/. The full usage guide is in SKILLS.md. The framework is open source at github.com/k9aif/k9-aif-framework.